Website Training
Steps to train Website URL:
- Go to "Website Links" section in Content Tab
- Type/Paste a valid website URL & Press enter.
- Mention any specific URL or keywords present in website to include or exclude. (Optional)
- Set website scraping depth.
- Click on "Save & Train".
Note:
- Website scraping can be done using 3 different settings
a) Default (7 Pages) - Scraping will be done till 7 pages depth
b) Unlimited Depth: All the URL present inside the added website will be scraped
c) Only Provided Page: Only the added website URL will be scraped
- Multiple URL's can be added by using semicolon as a separator

Website Training Limitations:
Here is a list of restrictions and content handling Issues that user can face while training the website content
- Website Restrictions:
- Captcha: The site may have CAPTCHA mechanisms to prevent scraping.
- IP Blocking: If you're making too many requests from a single IP, the site might block it temporarily or permanently.
- Robots.txt Restrictions: Some websites have a robots.txt file that disallows scraping.
- Rate Limiting: Websites often limit the number of requests you can make within a specific timeframe.
- User-Agent Blocking: Some sites block requests with specific user-agent headers, which scraping libraries often use by default.
- URL Structure or Invalid URLs:
- Broken or Invalid URLs: The URLs might be malformed or redirect to a broken link.
- Redirections: The URL could redirect multiple times, resulting in failures to retrieve content.
- Query Parameters: Some websites use dynamic content loaded via JavaScript, so query parameters might impact the result.
- Content Types and Formats:
- Non-HTML Content: Some URLs may return non-HTML content (PDFs, images, etc.) which cannot be easily scraped unless explicitly handled.
- Dynamic Content (JavaScript-based): If a site relies heavily on JavaScript to render its content (e.g., SPA apps), traditional scraping methods might fail.
- Obfuscated or Minified HTML: Sometimes content is purposefully obfuscated to prevent scraping, making it difficult to parse.
Advanced Website Scraper
Advanced mode introduced for scraping containing JavaScript enabled content and single page application (SPA) websites. Advanced scraping is done using Firecrawl services. Scraper type options (Basic & Advanced) dropdown available in Website Links section of Content Tab.

Value Delivered
- Increased run time AI accuracy in response generation due to higher content coverage
- Helps in faster delivery of use cases by reducing manual effort where content scraping required for Javascript enabled content & SPA websites
Basic Vs Advanced Usage Guidelines:
- Basic: Recommended when there is a simple website. Use it for first time training. If training is failing repeatedly or accuracy is less, then only move to Advanced
- Advanced: Recommended for website with JavaScript enabled content & single page application websites.
Key Limitation of Advanced Scraper:
- Max Limit on Website Pages in a single training - 3000
- Higher training time as compared to basic: ~ 30-40 minutes for 3000 pages
- Can not perform OCR on images
- Can not Scrape website hosted contents like pdf, docs, videos etc
- Can not scrape dynamic content and perform operations like Click, Scroll, Wait while extracting the content
Website Re-trainer (Developer Mode): Retraining Icon in the Website links section allows you to effortlessly retrain your AI agent's knowledge base with the latest content from previously added website URLs.
How it Works: When you click on the retraining icon to initiate the retraining, the existing content from the selected URLs will first be untrained. Following this, the latest content from those URLs will be trained, ensuring your agent has the latest information. Retraining is performed only on the selected content tag.
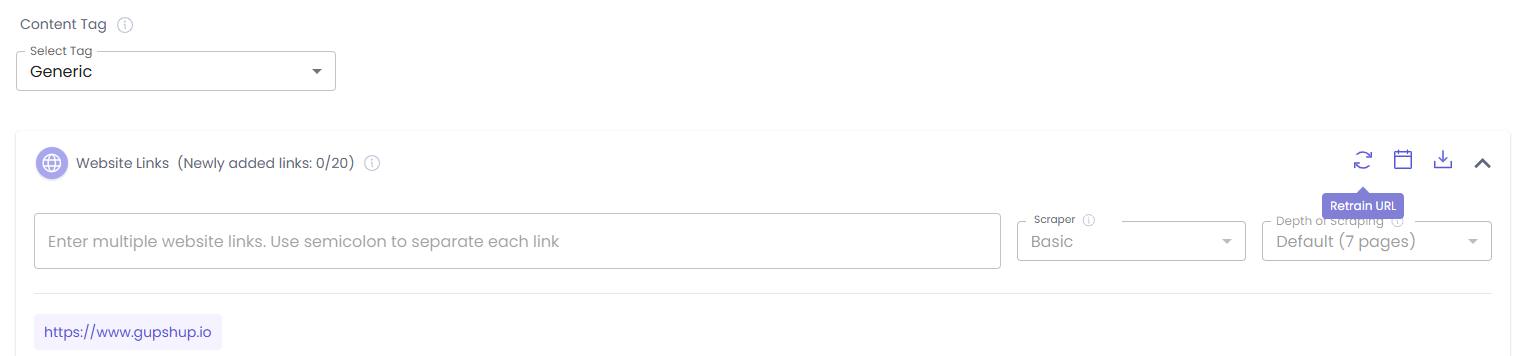
Key Behaviors & Availability of Retraining Icon:
- Enabled When Ready: The Retraining icon will be enabled only when the content tag has been successfully trained with website URLs.
- Disabled When Not Applicable:
-It will be disabled if no trained URLs are present in the content tag.
-The icon will also be disabled if you add new URLs, files, or raw text for training, as this signifies new training.
-It will be disabled while any training is in progress, including the retraining process itself.
Updated about 1 year ago