Document Training
Steps to train documents:
- Go to "Files" section in Content Tab.
- Click on choose File to upload single/multiple files.
- Click on "Save & Train".
Note:
- Allowed file format are .pdf, .txt, .csv.
- Maximum file size can be 20 MB.
- Maximum 20 files can be uploaded in a single training.

Advanced Pdf Parser
Advanced mode introduced for parsing pdfs containing images and complex tabular data to enhance content training capabilities. Advanced parsing is done using GPT-4O model. User can select Advanced option in the file upload modal which appears when user clicks on "Choose File" in Content Tab.
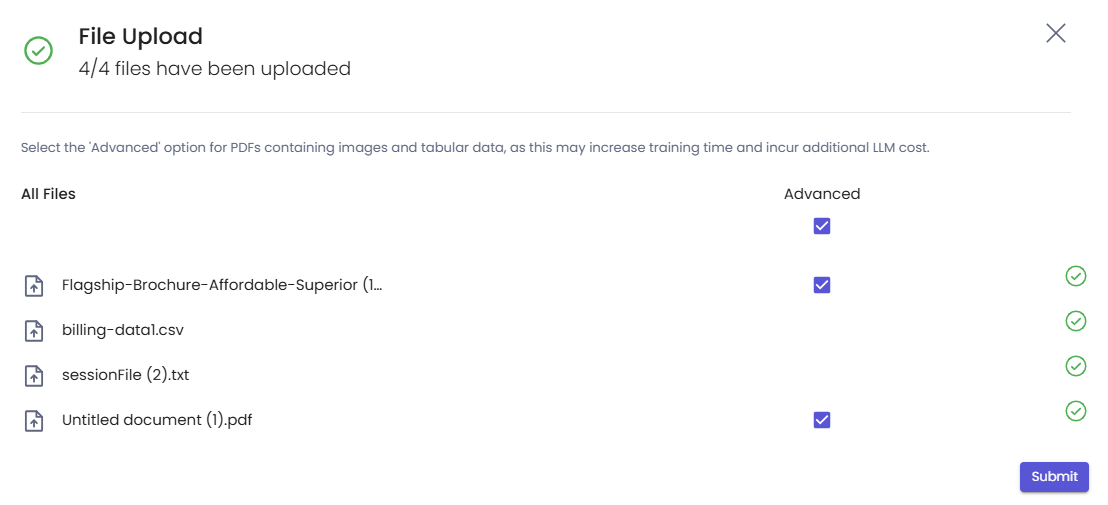
Value Delivered:
- Increased run time AI accuracy in response generation for PDF-based content
- Reduced manual effort during content training as no pre processing required for complex pdf
- Supports real-world business documents like, brochures, reports and more
Basic vs Advanced Usage Guidelines
Basic: Default Parsing option for all the pdf files. Simple pdfs which contains some images and mainly text can be easily parsed using Basic option.
Advanced: Use Advanced option only when PDF contains lots of images and nested tabular data (High training time & cost as compared to Basic)
Key Limitations:
- Parsing accuracy will be based on clarity of the image text
- Slow & Costly content extraction
- Final content extraction accuracy depends on the performance of LLM Model (Gpt-4O)
- Extraction is subjected to Azure content moderation policy - if it detects certain words in the content then it can get blocked
- Model may not perform optimally when handling images with text of non-Latin alphabets, such as Japanese or Korea
- The model may misinterpret rotated or upside-down text and images
- Not suggested for medical use cases like interpreting CT scan images
Updated about 1 year ago
Did this page help you?